DEIM: DETR with Improved Matching for Fast Convergence
动机与总结
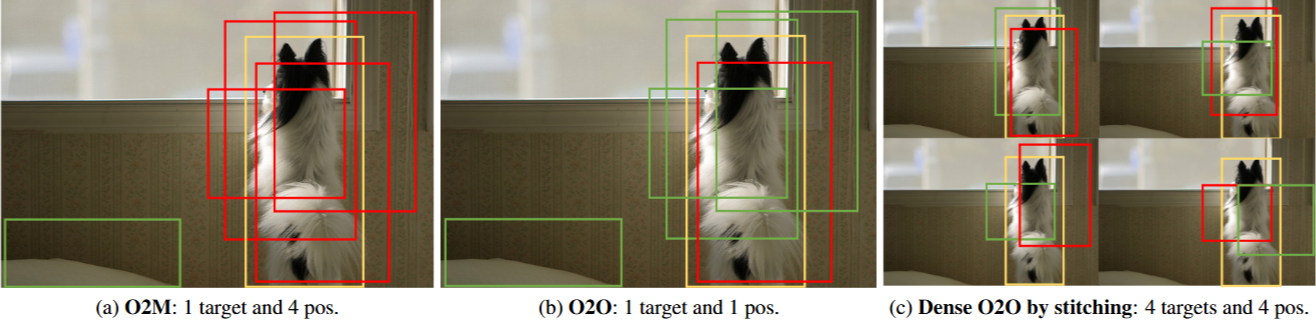
YOLO 模型的一对多 (O2M) 分配策略是每个目标框与多个 anchors 相关联。 这种策略被认为是有效的,因为它提供了密集的监督信号,从而加速了收敛并提高了性能。 然而,它会为每个对象生成多个重叠的 bounding boxes,这需要手动设计的 Non-Maximum Suppression (NMS) 来消除冗余,从而导致延迟和不稳定
基于 Transformer 的检测 (DETR) 范式利用多头注意力来捕获全局上下文,从而增强定位和分类效果。DETR 采用一对一 (O2O) 匹配策略,该策略利用 Hungarian算法在训练期间建立预测框和 ground-truth 对象之间的唯一对应关系,从而无需 NMS。然而,收敛速度慢仍然是 DETR 的主要限制之一,假设原因有两个方面。
- 稀疏监督:O2O 匹配机制为每个目标仅分配一个正样本,大大限制了正样本的数量。相比之下,O2M 生成的正样本数量是 O2O 的数倍。正样本的稀缺性限制了密集监督,从而阻碍了有效的模型学习——特别是对于小对象,密集监督对于性能至关重要。
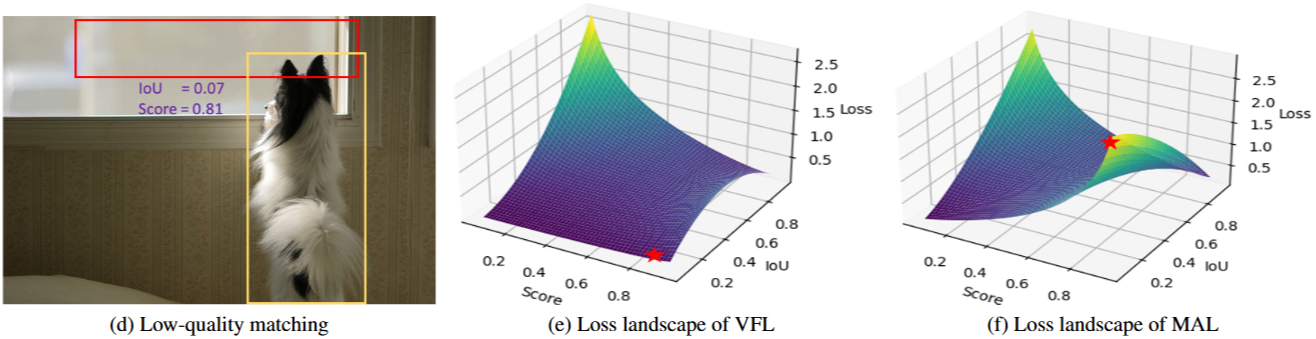
- 低质量匹配:与依赖密集 anchors(通常 > 8000)的传统方法不同,DETR 采用少量(100 或 300)随机初始化的 queries。这些 queries 缺乏与目标的空间对齐,导致训练中出现大量低质量匹配,其中匹配的框与目标的 较低但置信度评分较高。
一对一匹配限制了每个目标仅有一个正样本,提供的监督信息远少于 O2M,从而阻碍了优化。一些研究已经探索了在 O2O 框架内增加监督信息的方法。例如,Group DETR 采用了 “groups” 的概念来近似 O2M。它使用 组 queries,其中 ,并在每组内独立执行 O2O 匹配。这使得每个目标能够被分配到 个正样本。然而,为了防止组之间的通信,每组都需要一个单独的 decoder 层,最终导致 个并行的 decoders。H-DETR中的混合匹配方案与 Group DETR 类似。Co-DETR揭示了一种一对多分配方法有助于模型学习更具区分性的特征信息,因此它提出了一种协作混合分配方案,通过具有一对多标签分配的辅助头来增强 encoder 的表示,类似于 Faster R-CNN和 FCOS。现有的方法旨在增加每个目标的正样本数量,以增强监督信息。相比之下,我们的 Dense O2O 探索了另一个方向——增加每个训练图像的目标数量,以有效地提升监督效果。与现有方法需要额外的 decoders 或 heads,从而增加训练资源消耗不同,我们的方法是免计算的。
稀疏和随机初始化的 query 缺乏与目标的空间对齐,导致产生大量低质量匹配,从而阻碍模型收敛。一些方法已经将先验知识引入到 query 初始化中,例如 anchor queries、DAB-DETR、DN-DETR 和 dense distinct queries。最近,受到 two-stage 范式的启发,DINO 和 RT-DETR等方法利用 encoder 密集输出中排名靠前的预测来改进 decoder 的 queries。这些策略使得 query 初始化更有效,使其更接近目标区域。然而,低质量匹配仍然是一个重大挑战。在 RT-DETR中,Varifocal Loss (VFL) 被用来减少分类置信度和框质量之间的不确定性,从而提高实时性能。然而,VFL 主要是为低质量匹配较少的传统检测器设计的,并且侧重于高 IoU 的优化,由于其极小且平坦的损失值,导致低 IoU 的匹配未被充分优化。在这些先进初始化方法的基础上,我们引入了一种 matchability-aware loss,以更好地优化不同质量水平的匹配,从而显著提高 Dense O2O 匹配的有效性。
- 🚀 本文介绍了一种名为DEIM的创新训练框架,旨在加速基于Transformer架构的实时目标检测模型的收敛速度。
- 🎯 DEIM采用密集的一对一匹配策略,通过增加每个图像中的正样本数量来缓解DETR模型中固有的稀疏监督问题,并使用可感知匹配度的损失函数(MAL)来优化不同质量水平的匹配。
- 🏆 在COCO数据集上的实验结果表明,DEIM能够显著提升RT-DETR和D-FINE的性能,同时减少50%的训练时间,并在实时目标检测领域树立了新的基准。
密集O2O匹配 (Dense O2O Matching):
方法: 通过使用mosaic和mixup等数据增强技术,将多张图片拼接或融合到一张图片中,增加图像中的目标数量。例如,mosaic将四张图片拼接成一张,使目标数量变为原来的四倍。
公式表达: 假设原始图像有个目标,密集O2O的目标数量变为,其中取决于增强技术,例如mosaic通常。 训练损失函数可以表示为:
其中, 是目标总数, 是第 个目标的匹配数, 表示第 个目标的第 个匹配, 表示第 个真实标签, 是损失函数。由于是O2O匹配,所以
Matchability-Aware Loss (MAL):
VariFocal Loss (VFL) [40] 基于 FL [19] 构建,已被证明可以提高目标检测性能,尤其是在 DETR 模型中。VFL 损失表示为:
其中,q 表示预测边界框与其目标框之间的 IoU。对于前景样本 (q > 0),目标标签设置为 q,而背景样本 (q = 0) 的目标标签为 0。VFL 结合 IoU 来提高 DETR 中 queries 的质量。然而,VFL 在优化低质量匹配时存在两个主要局限性:
- 低质量匹配。VFL 主要关注高质量匹配 (高 IoU)。对于低质量匹配 (低 IoU),损失仍然很小,从而阻止模型改进低质量框的预测。对于低质量匹配(具有低 IoU,例如,图 2d),损失仍然很小(在图 2e 中用 ⋆ 标记)。
- 负样本。VFL 将没有重叠的匹配视为负样本,这减少了正样本的数量并限制了有效的训练。 对于传统的检测器来说,这些问题并不那么严重,因为它们具有密集的 anchors 和一对多的分配策略。然而,在 DETR 框架中,queries 是稀疏的,并且匹配更加严格,这些局限性变得更加明显。
与VFL相比,我们引入了一些细微但重要的更改。 具体来说,目标标签已从 修改为 ,从而简化了正样本和负样本的损失权重,并删除了用于平衡正样本和负样本的超参数 。 这种改变有助于避免过度强调高质量的框,并改善整体训练过程。 从VFL(图2e)和MAL(图2f)之间的损失情况可以很容易地看出这一点。
代码
DEIM或者是传统的DETR式的目标检测器由三个部分组成:
- backbone
- encoder:HybridEncoder
- decoder
对于类别的损失函数MAL相比于VFL的区别在于VFl对于BCE的权重,匹配的用target_score(iou),没有匹配的用pred_score(logits);而MAL计算IOU时会进行一个幂运算(对于小iou的匹配target_score会更小),匹配的会用targe(0-1编码),相比于之前对于HungarianMatch匹配的结果给与更大的权重
- 概率比较低,iou比较大 Loss = −qγ log(p) 大
- 概率比较高,iou比较低 Loss = − (1 − qγ ) log(1 − p) 大
def loss_labels_vfl(self, outputs, targets, indices, num_boxes, values=None):
assert 'pred_boxes' in outputs
idx = self._get_src_permutation_idx(indices)
if values is None:
src_boxes = outputs['pred_boxes'][idx]
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0)
ious, _ = box_iou(box_cxcywh_to_xyxy(src_boxes), box_cxcywh_to_xyxy(target_boxes))
ious = torch.diag(ious).detach()
else:
ious = values
src_logits = outputs['pred_logits']
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o
target = F.one_hot(target_classes, num_classes=self.num_classes + 1)[..., :-1]
target_score_o = torch.zeros_like(target_classes, dtype=src_logits.dtype)
target_score_o[idx] = ious.to(target_score_o.dtype)
target_score = target_score_o.unsqueeze(-1) * target
pred_score = F.sigmoid(src_logits).detach()
weight = self.alpha * pred_score.pow(self.gamma) * (1 - target) + target_score # iou越高的函数会被给予越高的权重
loss = F.binary_cross_entropy_with_logits(src_logits, target_score, weight=weight, reduction='none')
loss = loss.mean(1).sum() * src_logits.shape[1] / num_boxes
return {'loss_vfl': loss}
def loss_labels_mal(self, outputs, targets, indices, num_boxes, values=None):
assert 'pred_boxes' in outputs
idx = self._get_src_permutation_idx(indices)
if values is None:
src_boxes = outputs['pred_boxes'][idx]
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0)
ious, _ = box_iou(box_cxcywh_to_xyxy(src_boxes), box_cxcywh_to_xyxy(target_boxes))
ious = torch.diag(ious).detach()
else:
ious = values
src_logits = outputs['pred_logits']
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o
target = F.one_hot(target_classes, num_classes=self.num_classes + 1)[..., :-1]
target_score_o = torch.zeros_like(target_classes, dtype=src_logits.dtype)
target_score_o[idx] = ious.to(target_score_o.dtype)
target_score = target_score_o.unsqueeze(-1) * target
pred_score = F.sigmoid(src_logits).detach()
target_score = target_score.pow(self.gamma)
if self.mal_alpha != None:
weight = self.mal_alpha * pred_score.pow(self.gamma) * (1 - target) + target
else: # 匹配的用target或target_score,没有匹配的用pred_score(logits)
weight = pred_score.pow(self.gamma) * (1 - target) + target
# print(" ### DEIM-gamma{}-alpha{} ### ".format(self.gamma, self.mal_alpha))
loss = F.binary_cross_entropy_with_logits(src_logits, target_score, weight=weight, reduction='none')
loss = loss.mean(1).sum() * src_logits.shape[1] / num_boxes
return {'loss_mal': loss}